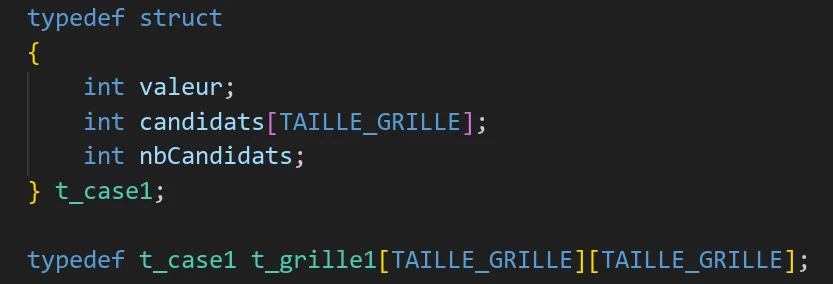
Lorsqu’on joue au sudoku, on a dans chaque cases vides des valeurs candidates. J’ai testé deux manières d’implémenter le système de valeurs candidates. La première façon consiste à stocker les valeurs candidates dans un tableau.
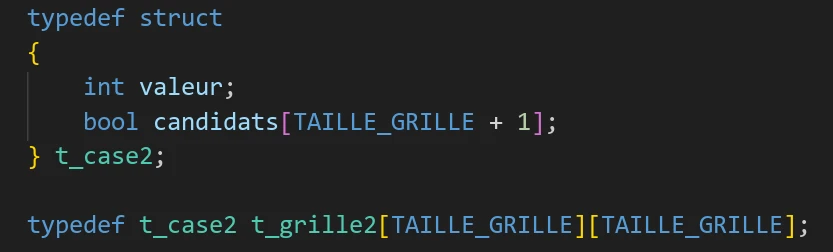
La deuxième façon consiste à utiliser un tableau de booléens. Chaque booléen du tableau correspond à une valeur candidate et indique si oui ou non elle est candidate.
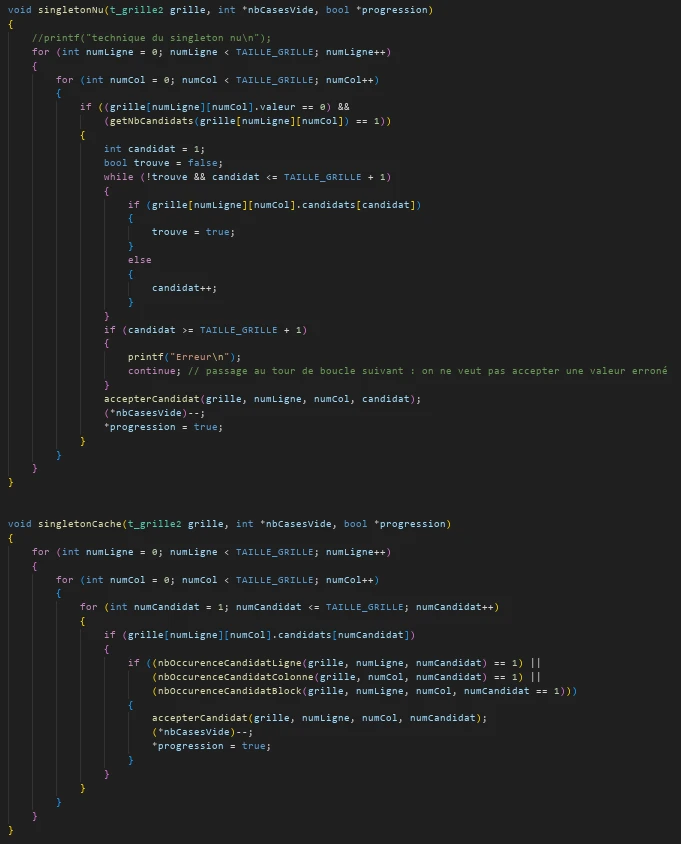
Une fois le système de valeurs candidates mis en place,
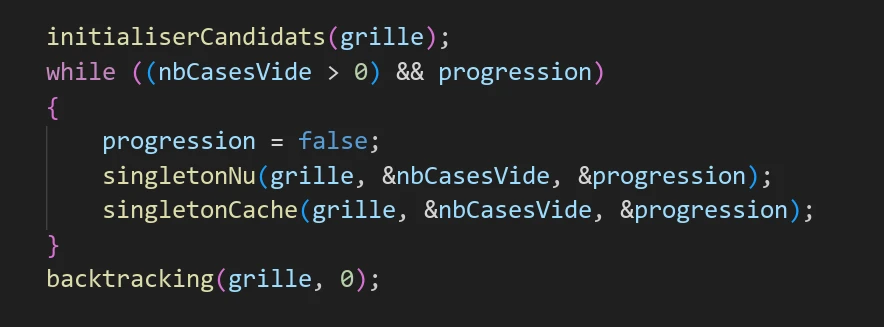
j’ai fait un programme qui utilise des techniques du sudoku
pour remplir une grille. Ici, j’ai implémenter deux
méthodes : le singleton nu, et le singleton caché.
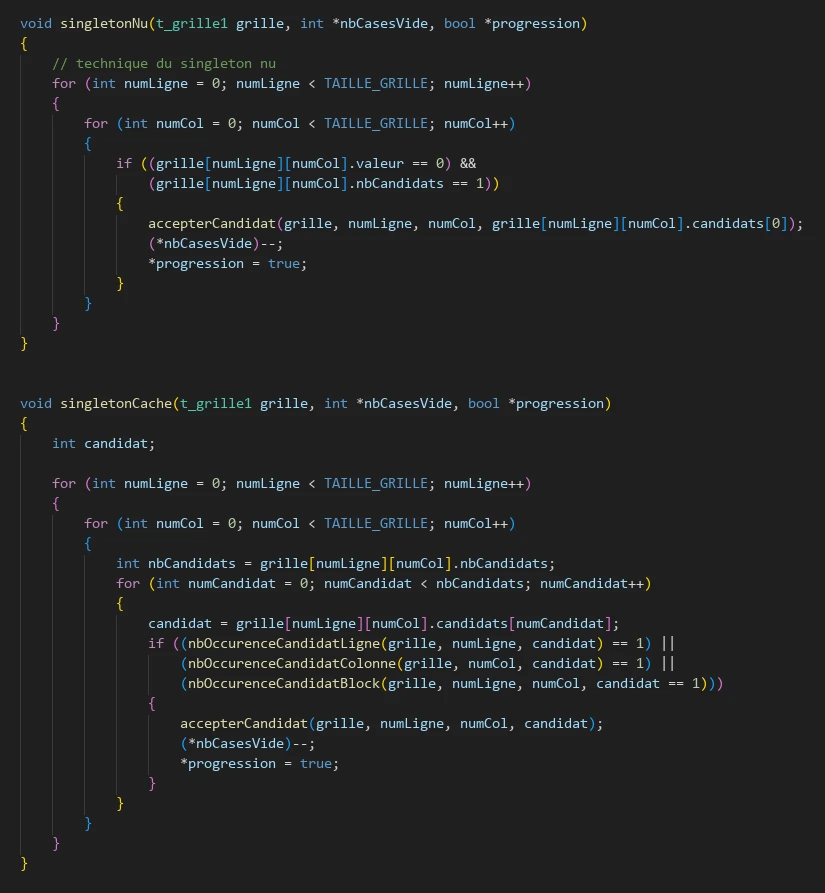
La technique du singleton nu consiste à chercher dans la
grille des cases qui n’ont qu’un seul candidat.
La technique du singleton caché recherche dans la grille
une case qui à un candidat qui n’est pas présent ailleurs
sur la ligne, la colonne, et le groupe de cases local.
Pour compléter mon programme, j’ai utilisé un autre
algorithme qui trouve systématiquement une solution
s’il en existe, mais qui est extrêmement lent. Il
s’agit de l’algorithme de backtracking (retour sur
trace en français). Cet algorithme consiste à essayer
une solution, et si cette solution mène à une impasse,
on revient en arrière.
De plus, les programmes ne complètent pas entièrement les
grilles.

Pour compléter mon programme, j’ai utiliser un autre algorithme
qui trouve systématiquement une solution si il en existe, mais
qui est extrêmement lent. Il s’agit de l’algorithme de
backtracking (retour sur trace en français). Cet algorithme
consiste à essayer une solution, et si cette solution mène à
une impasse, on revient en arrière.
Après avoir testé cet algorithme, j’ai remarqué qu’il était
effectivement très lent. Environ de 5 s pour la grille la plus
simple, et plus de 30 minutes pour la grille la plus compliquée.
Mon programme final utilise d’abord les techniques du sudoku. Lorsque ces techniques n’arrivent plus à remplir la grille, l’algorithme de backtracking se charge du reste.